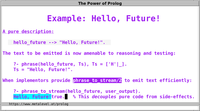
The Future of Prolog
DUCUNT VOLENTEM FATA NOLENTEM TRAHUNT
(Attributed to Lucius Annaeus Seneca)
Lessons from the past
Prolog is harder to learn than many other programming languages.
In part, this is due to inherent reasons: Prolog is simpler and
more powerful than many other programming languages, and so it
takes longer to get used to this if you are more familiar with
low-level languages.
However, a far more important cause is found in limitations of
existing teaching material: In many cases, Prolog is being taught
exactly like it was taught in the 1980s and 1990s. Outdated
teaching material leads to broken promises: The use of low-level
and impure language features complicates or prevents logical
reasoning about Prolog programs, forcing students to think
procedurally about their programs instead of declaratively.
In the past, this has resulted in a lot of frustration, wrong
impressions and coding horror. For
beginners, it is easy to get sidetracked and start wrestling with
low-level issues while losing sight of much more important
principles. Do not fall into this trap!
Prolog is also hard to teach, since it is hard to keep all
informal statements you make about Prolog programs
sufficiently general to cover all possible
usage modes. Conscious effort is necessary to convey this
generality to beginners.
Current developments
In the Prolog community, most current developments are focused on
increasing logical purity, and
making pure code more feature-rich and efficient.
| Video: |
|
The ISO
standardization process is an important means to improve
compatibility between different Prolog systems.
| Video: |
|
Web services and data analysis are
increasingly relevant application areas for Prolog.
One of the most exciting developments for efficient data and text
analysis with Prolog is the implementation of a very compact
representation of strings as lists of
characters so that DCGs can be applied efficiently to files and
streams. Scryer Prolog is the first system that implements
this representation, and it is to be hoped that other Prolog
systems will also adopt it. The ultimate goal of this development
is a Prolog system's ability to directly apply a DCG to file
contents by using the system-call mmap for very
efficient access. Trealla Prolog is the first—and
currently still only—Prolog system that provides this.
Most recent and ongoing developments of Prolog happen in
universities and in institutions that are closely associated
with academia. Important contemporary research areas include
probabilistic logic programming, answer set
programming (ASP) and language dialects that satisfy certain
safety criteria or other interesting declarative properties.
As an application programmer and Prolog practitioner, you can
contribute to these developments by getting acquainted with modern
Prolog features, applying them in your own programs, and
discussing opportunities for improvements with your
Prolog vendor. Continuous and wide-spread usage helps to
ensure that these features are constantly improving.
The begin
The advent and wide availability of new, declarative language
features justify and moreover necessitate that
we teach Prolog differently than we did in
the past.
| Video: |

|
Nowadays, it is becoming increasingly inappropriate to dedicate a
significant portion of your lectures to explaining the intricacies
of low-level language constructs that have long
been superseded by more general replacements. The time is
better spent elsewhere: in explaining the foundations of logic
programming in such a way that modern language constructs
are naturally covered. This retains full generality and
allows both declarative and procedural readings
instead of precluding one or the other.
To really appreciate modern Prolog features, you also have to
take into account their history: Previous generations of
Prolog instructors were acutely aware of the declarative
limitations associated with the constructs they were teaching, but
had no other options. In many cases, the instructors themselves
were also among the pioneers in the difficult search for more
elegant and more general constructs.
For instance, consider the following section from
a manuscript by Richard O'Keefe, written no
later than 1984:
Instantiation Faults
The fifth kind of error is when a question has too many variables in it.
Now this logically speaking is no error at all. The question "plus(X,X,Y)"
has a perfectly good set of solutions {(X,Y)|X is an integer and Y=2*X}.
It is evident from this draft that very declarative features have
been anticipated for several decades. It has simply taken a
certain amount of time until the techniques that were
envisioned and even outlined by many pioneers were
fully realized. Today, we get in full accordance with what
the draft envisaged:
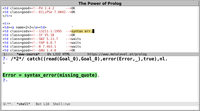
?- X + X #= Y.
clpz:(2*X#=Y).
By now, declarative features like constraints are widely spread
and available at least to some extent in all popular Prolog
systems. For many people working in declarative language research,
this is a dream come true, and still materializing. These
features are meant to be used. I mean not only as
interesting curiosities, but as integral parts of the
language. Prolog systems that do not yet include some of these
features will adopt them as they become
more popular.
In the future, the most influential Prolog books will be those
which most explicitly expose the pure core
of Prolog and the unique advantages and
application opportunities of logic programming and
constraints, such as:
By fully embracing such concepts and using them to their utmost
advantage, future generations may at last behold and
benefit from the true power of Prolog.
More about Prolog
Main page